The Accountability Dimension
Why Catching Errors Is the Most Important AI Collaboration Skill
The brief looked good. The research was thorough, the structure was clean, the citations were specific and authoritative. You forwarded it to the client.
Three days later, you find out one of the cited cases doesn't exist. The AI generated a plausible-sounding reference, formatted it correctly, and you sent it along. You were busy. The output looked polished. Nothing triggered a second look.
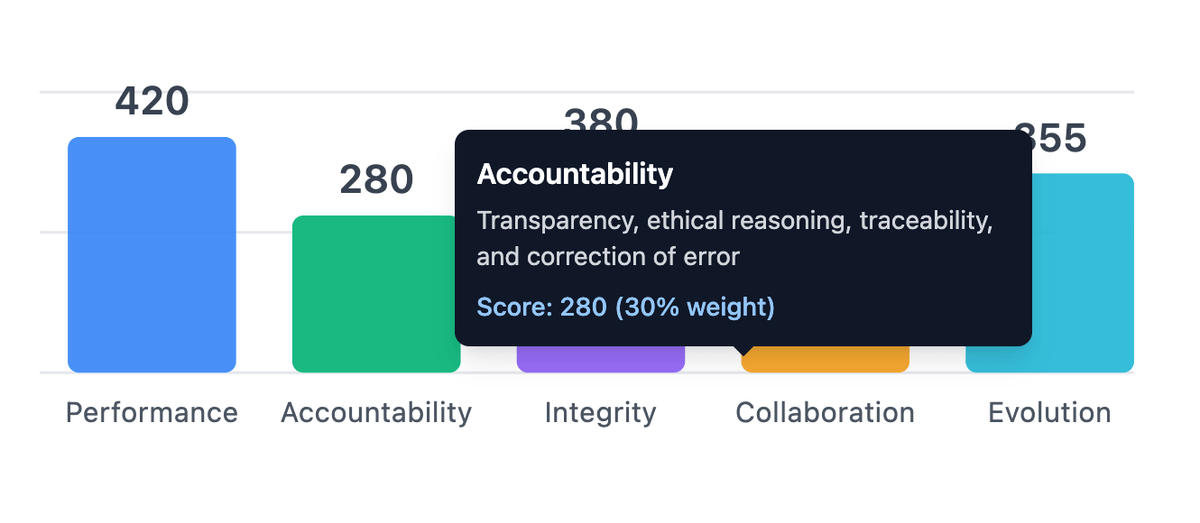
That's the Accountability gap. And it's why the Accountability dimension carries more weight in PAICE than any other — 30 percent of your total score.
What Accountability Means in PAICE
Accountability is not about blame. In the PAICE framework, it measures something concrete and behavioral: whether you verify AI output before acting on it, and whether you catch errors when they're present.
This distinction matters. Accountability doesn't measure whether you feel responsible for your work. It measures whether your verification behaviors actually intercept errors before they cause problems.
Error Detection
The most direct component: when AI produces something wrong, do you notice? This shows up in the assessment through injected errors — factual mistakes, fabricated citations, incorrect calculations — that are deliberately introduced to see whether you catch them.
Error detection is not about being suspicious of everything. It's about maintaining an active, professional relationship with the information in front of you. Reading critically. Noticing when something doesn't add up. Following up on the specific claims that most need to be right.
Verification Behavior
Beyond catching errors that surface naturally, Accountability measures whether you verify proactively. Do you check citations before forwarding them? Do you validate figures against their stated sources? Do you test AI's factual claims rather than accepting them because they sound credible?
Verification behavior is the habit layer. Error detection tells you whether you noticed a problem. Verification behavior tells you whether you built the habits that make noticing likely.
Calibrated Skepticism
AI systems do not signal uncertainty the way humans do. A person who isn't sure about a fact will often hedge, qualify, or flag that they need to check. AI delivers fabricated citations with exactly the same confident tone as verified ones. Calibrated skepticism means recognizing this — and adjusting your review intensity accordingly.
High Accountability professionals develop an instinct for which outputs deserve more scrutiny: claims that are suspiciously specific, conclusions that perfectly match what they wanted to hear, references that cannot easily be traced. This is a refined professional judgment about where verification effort is best directed, not blanket distrust.
Why 30% Weight
Accountability is the highest-weighted dimension in PAICE. Understanding why requires understanding what's at stake when verification fails.
The Error Doesn't Announce Itself
Human errors often have tells. A draft from a junior colleague might use hedging language when the writer is unsure. A rough calculation might carry a question mark. Even a confident assertion from a person you trust can be double-checked by asking them directly.
AI errors have no tells. The fabricated case citation is formatted identically to the real one. The incorrect dosage figure carries no asterisk. The outdated regulatory reference reads with the same authority as current guidance. The error is invisible until you look for it, and AI gives you no signal about when to look.
This is the fundamental problem that Accountability addresses. Professional workflows have always depended on error signals — on the cues that tell you where to apply scrutiny. AI eliminates those cues. A professional who doesn't replace them with deliberate verification habits is not applying professional judgment to AI output. They're forwarding it.
What Leaves Your Desk Is Your Work
When an AI-generated error reaches a client, a court, a patient record, or a regulatory submission, it carries your professional signature. The origin in AI is not a mitigating factor. In most regulated professions, professional standards make clear that responsibility for the work product rests with the licensed professional, not the tool they used.
This is not a new principle. Lawyers have always been responsible for research their paralegals produce. Physicians have always been responsible for analyses from their clinical staff. The standard is the same with AI — what's new is the scale at which plausible-looking errors can be generated and the speed at which they can propagate.
The 55% Foundation
Accountability (30%) and Integrity (25%) together represent 55% of your PAICE score. This is intentional. These two dimensions cover the behaviors most directly connected to professional risk in AI-assisted work: catching errors before they leave (Accountability) and maintaining information quality as it flows through your workflow (Integrity).
For professionals who are individually licensed and personally liable, these behaviors determine whether AI adoption strengthens or undermines their practice. Performance, Collaboration, and Evolution matter — but they operate on top of this foundation.
What High Accountability Looks Like
High Accountability is the behavior of someone who applies consistent professional standards regardless of whether the source is human or machine.
Cross-checking citations and specific figures. When AI provides a case reference, a statistic, or a regulatory citation, a high-Accountability professional checks it. Not every output in exhaustive detail — but the claims that are most load-bearing and most likely to damage credibility if wrong.
Slowing down on suspiciously clean outputs. A research summary that covers exactly the right cases, in exactly the right order, with perfectly balanced arguments on each side should trigger a second look. Real research has rough edges. Outputs that seem too perfectly constructed may reflect AI's preference for balanced, structured responses rather than the actual landscape of the topic.
Testing conclusions that match prior expectations. Confirmation bias and AI output are a dangerous combination. When AI tells you exactly what you wanted to hear, that's precisely when verification matters most. High-Accountability professionals are alert to the moment when the output feels too convenient.
Asking where the information came from. "According to the 2024 regulatory guidance" is a claim, not evidence. High-Accountability professionals treat AI-provided sources as hypotheses to be verified, not facts to be forwarded.
Maintaining verification standards under time pressure. This is where Accountability is most tested. When you're busy and the output looks good, skipping verification is tempting. High-Accountability professionals have built habits that make verification non-optional — not because they're cautious by temperament, but because they've internalized that the cost of a missed error is always higher than the cost of a quick check.
What Low Accountability Looks Like
Low Accountability patterns are common, understandable, and often invisible to the person demonstrating them.
Treating confident tone as an accuracy signal. AI produces text that reads authoritatively. Low-Accountability professionals accept this tone as evidence of reliability. This is the most common Accountability failure in PAICE assessments, because it's a natural cognitive response to text that sounds like it was written by someone who knows what they're talking about. Confidence is a property of language model output. It is not an indicator of factual correctness.
Assuming polished format means verified content. Well-formatted output — headers, numbered lists, citations in the right places — carries an implicit credibility signal. Low-Accountability professionals register the format as a quality marker rather than a presentation choice.
Deferring verification to later. "I'll double-check this before it goes out" is an intention, not a habit. Under time pressure, later often doesn't arrive. Low Accountability shows up in the gap between what people intend to verify and what they actually verify.
Relying on AI self-assessment. Asking AI "is this accurate?" is not verification. AI will often confirm its own output as accurate, and self-referential checking is not checking.
Accepting outputs in domains where expertise is thinner. Low-Accountability patterns are most pronounced in areas where the professional feels less confident in their own judgment. If you can't easily evaluate whether an AI-generated analysis is correct, you may be tempted to assume it is. Professional responsibility doesn't pause at the edges of your confidence.
Why Accountability Is the Hardest Dimension to Self-Assess
Most professionals believe their Accountability habits are better than their PAICE scores typically reflect. This is not self-deception. It's a structural feature of how AI errors work.
When you miss an error a human colleague made, you often find out. A follow-up question exposes the gap. A client catches it. A supervisor flags it in review. The feedback loop closes.
When you miss an AI error, the feedback loop often stays open. The fabricated citation goes into a brief that settles before anyone checks the references. The incorrect statistic gets repeated in a slide deck and never sourced. The outdated regulatory reference shapes a recommendation that no one revisits. The absence of a complaint is not evidence that everything was correct.
This is why Accountability scores often surprise people. The professionals who score lower are not those who know they're cutting corners. They're those who have never received the feedback that would tell them their verification habits have gaps.
How to Develop Your Accountability Score
Accountability requires a process, not just an intention. The goal is not exhaustive verification of everything — that would be paralyzing. The goal is calibrated, content-type-specific verification practices that intercept errors where they matter.
Build content-type-specific checklists. Citations need different verification than figures, which need different verification than regulatory references. A lawyer verifying a case citation should be checking whether the case exists, whether the holding is accurately characterized, and whether the jurisdiction is correct. A financial professional verifying an AI-generated figure should trace it to a primary source, not another AI-generated summary. Define what verification means for your most common AI-assisted output types, then apply it consistently.
Practice the spot-check before full review. The skill is knowing which elements carry the most risk if wrong and checking those first. Before using any AI output, ask: what is the single claim here that would cause the most damage if it's incorrect? Start your verification there.
Learn to recognize AI overconfidence markers. Suspiciously specific statistics with precise decimal points. Perfectly balanced arguments that present exactly two strong positions on each side. Citations that are correctly formatted but difficult to locate. Conclusions that precisely match your stated objectives. These patterns don't prove error — but they warrant a closer look.
Make verification a discrete workflow step. The professionals who score highest have made verification a specific, named step in how they handle AI output — not an intention that competes with time pressure. Even a 90-second check on the three most critical claims in an AI output is more reliable than a general sense of having reviewed carefully.
Run periodic calibration exercises. Once a month, take an AI output you already used and verify it against primary sources. What did you miss? What would you have caught with a more structured review? These exercises build the pattern recognition that makes real-time verification faster and more effective over time.
Accountability and Integrity
These two dimensions are closely related, and the Integrity dimension post covers their interaction in detail. The summary: Accountability measures whether you catch errors; Integrity measures whether you maintain information quality as it flows through your workflow. High Accountability means you're detecting problems. High Integrity means you're preventing them from propagating.
If you scored differently on Accountability and Integrity, the profiles are informative. High Accountability with lower Integrity suggests you catch errors well in the moment but may be less consistent about verification before work reaches others. High Integrity with lower Accountability suggests strong information handling habits but gaps in active error detection during live AI interaction.
What This Means for Your Practice
A lower-than-expected Accountability score is not a character assessment. It reflects specific, observable behaviors during the assessment — and those behaviors can be developed.
The professionals who score highest on Accountability are not those who distrust AI or who slow their work to a crawl with exhaustive review. They're those who have built targeted verification habits calibrated to the actual risk profile of their work: checking the claims that matter most, at the moment before they matter, as a built-in part of how they handle AI output.
Caught errors stay caught. Forwarded errors become your errors. The habit that separates those outcomes is what Accountability measures.
Want to see where your verification habits actually land? Take the PAICE assessment to get detailed feedback on your Accountability behaviors and all four other dimensions.
Get Involved:
- Take the assessment (free, always)
- Explore our Baseline offerings (for organizations)
- Read the whitepaper (comprehensive framework)
- Contact us about your specific requirements
Recommended Reading
📖 Dimension Deep Dives:
- The Performance Dimension - How PAICE measures communication clarity and efficiency in AI interactions
- The Integrity Dimension - How PAICE measures information quality and attribution in AI collaboration
- The Collaboration Dimension - How PAICE measures iteration, feedback, and working effectively with AI
- The Evolution Dimension - How PAICE measures whether your collaboration skills adapt as AI capabilities change
📖 Understanding the Dimensions:
- The Five Dimensions of AI Collaboration - How all five PAICE dimensions work together
- What PAICE Tests For - The behavioral signals behind every score
📖 Scores and Development:
- Accounting For Accountability - Why Accountability scores lower than other dimensions and what to do about it
- Verification Workflows That Actually Work - Practical verification practices for AI-assisted professional work
- What Your PAICE Score Really Means - Interpreting your results effectively
- Improving Your PAICE Score - Practical strategies for skill development
متجسس لیکن وقت کم ہے؟
3 منٹ کا PAICE Pulse کریں — ایک فوری اعتماد چیک جو یہ ظاہر کرتا ہے کہ آپ اپنی AI تعاون کی پوزیشن کو کیسے دیکھتے ہیں۔ لاگ ان کی ضرورت نہیں۔